Código legible en R
6 consejos simples y prácticos para escribir mejor código
#> #> ----- #> Hola a todas y todos! #> ------ #> \ ^__^ #> \ (oo)\ ________ #> (__)\ )\ /\ #> ||------w|#> || ||Analytics Developer
( package developer) en ![]()
🥐 ☕ amante del pan y el café.
- Mantenemos un ecosistema de más de 10 paquetes en R.
- Mantenemos un ecosistema de más de 10 paquetes en R.
- Desarrollamos código de forma colaborativa en un equipo de 4 integrantes.
- Mantenemos un ecosistema de más de 10 paquetes en R.
- Desarrollamos código de forma colaborativa en un equipo de 4 integrantes.
- Otros equipos de la organización pueden ver tu código.
- Mantenemos un ecosistema de más de 10 paquetes en R.
- Desarrollamos código de forma colaborativa en un equipo de 4 integrantes.
- Otros equipos de la organización pueden ver tu código.
- Los paquetes son usados para generar cerca de 10,000 análisis al mes.
- Mantenemos un ecosistema de más de 10 paquetes en R.
- Desarrollamos código de forma colaborativa en un equipo de 4 integrantes.
- Otros equipos de la organización pueden ver tu código.
- Los paquetes son usados para generar cerca de 10,000 análisis al mes.
Seguir las buenas prácticas de escritura de código se vuelve imperativo
- Mantenemos un ecosistema de más de 10 paquetes en R.
- Desarrollamos código de forma colaborativa en un equipo de 4 integrantes.
- Otros equipos de la organización pueden ver tu código.
- Los paquetes son usados para generar cerca de 10,000 análisis al mes.
Seguir las buenas prácticas de escritura de código se vuelve imperativo
Esta keynote está basada en el libro The Art of Readable Code (2012) de Dustin Boswell y Trevor Foucher.

El Teorema fundamental de la legibilidad
El código debe ser escrito para minimizar el tiempo que le tomaría a alguien más entenderlo. 👩💻
El Teorema fundamental de la legibilidad
El código debe ser escrito para minimizar el tiempo que le tomaría a alguien más entenderlo. 👩💻
¿Y si yo soy el único que lee el código que escribo?
El Teorema fundamental de la legibilidad
El código debe ser escrito para minimizar el tiempo que le tomaría a alguien más entenderlo. 👩💻
¿Y si yo soy el único que lee el código que escribo?

1. Estética

Un buen código debe ser "agradable a la vista".
Un buen código debe ser "agradable a la vista".
Específicamente, hay un par de principios que deberíamos seguir:
Un buen código debe ser "agradable a la vista".
Específicamente, hay un par de principios que deberíamos seguir:
- Utilizar un diseño consistente, con patrones a los que el lector pueda acostumbrarse.
Un buen código debe ser "agradable a la vista".
Específicamente, hay un par de principios que deberíamos seguir:
Utilizar un diseño consistente, con patrones a los que el lector pueda acostumbrarse.
Si es posible, apegarse a lo estándares de la comunidad de R, recomendable The tidyverse style guide (https://style.tidyverse.org).
Un buen código debe ser "agradable a la vista".
Específicamente, hay un par de principios que deberíamos seguir:
Utilizar un diseño consistente, con patrones a los que el lector pueda acostumbrarse.
Si es posible, apegarse a lo estándares de la comunidad de R, recomendable The tidyverse style guide (https://style.tidyverse.org).
¡Trivia!
¡Trivia!
max_by = function(data,var,by) data %>% group_by(by) %>% summarise(maximum=max(var,na.rm=T))
¡Trivia!
max_by = function(data,var,by) data %>% group_by(by) %>% summarise(maximum=max(var,na.rm=T))
# Bien :)max_by <- function(data, var, by) { data %>% group_by(by) %>% summarise(maximum = max(var, na.rm = TRUE))}Ideas clave
- Todo el mundo prefiere leer un código que sea estéticamente agradable. Si "formateas" tu código de forma coherente y con sentido, lo harás más fácil y rápido de leer.
Ideas clave
- Todo el mundo prefiere leer un código que sea estéticamente agradable. Si "formateas" tu código de forma coherente y con sentido, lo harás más fácil y rápido de leer.
- Un estilo consistente es más importante que el estilo "correcto"
Ideas clave
- Todo el mundo prefiere leer un código que sea estéticamente agradable. Si "formateas" tu código de forma coherente y con sentido, lo harás más fácil y rápido de leer.
- Un estilo consistente es más importante que el estilo "correcto"
- Hacer check de linternas sobre los scripts (paquete)

2. Da información al nombrar
obtenDatos <- function() { ...}obtenDatos <- function() { ...}¿Va a descargar datos? ¿Los datos serán un data.frame, un tibble o un data.table?
obtenDatos <- function() { ...}¿Va a descargar datos? ¿Los datos serán un data.frame, un tibble o un data.table?
getTreeSize <- function() { ...}obtenDatos <- function() { ...}¿Va a descargar datos? ¿Los datos serán un data.frame, un tibble o un data.table?
getTreeSize <- function() { ...}¿Qué queremos del árbol realmente?
obtenDatos <- function() { ...}¿Va a descargar datos? ¿Los datos serán un data.frame, un tibble o un data.table?
getTreeSize <- function() { ...}¿Qué queremos del árbol realmente?
Nombres como heightTree() o numNodesTree() dejarían más claro la intención de lo que significa el tamaño del árbol.
| Palabras | Alternativa |
|---|---|
| send | search, extract, distribute |
| find | search, extract, locate, recover |
| start | create, begin, open |
| make | create, set-up, build, generate, add |
Nombres temporales
Nombres como temp, val, y x usualmente significan cosas como “no pude pensar en otro nombre”.
Nombres temporales
Nombres como temp, val, y x usualmente significan cosas como “no pude pensar en otro nombre”.
norma_euclideana <- function(v) { final <- 0 for(i in seq_along(v)) { final <- final + v[i] ^ 2 } sqrt(final)}Nombres temporales
Nombres como temp, val, y x usualmente significan cosas como “no pude pensar en otro nombre”.
norma_euclideana <- function(v) { final <- 0 for(i in seq_along(v)) { final <- final + v[i] ^ 2 } sqrt(final)}La única información que aporta la variable final, es que será usada para retornar el valor final dentro de un cálculo.
suma_cuadrado <- suma_cuadrado + v[i]^2
Pensemos en esta línea
final <- final + v[i]
Pensemos en esta línea
final <- final + v[i]
el bug sería más fácil de identificar con...
suma_cuadrado <- suma_cuadrado + v[i]
¿Dónde está el cuadrado en suma cuadrado?
Pueden haber excepciones...
if (right < left) { temp <- right right <- left left <- temp}El nombre es un comentario
El nombre es un comentario
temp <- calcularPrecioUSD(casa_mts, casa_num_cuartos)valor_final <- temp * tasa_usd_a_pesosEl nombre es un comentario
temp <- calcularPrecioUSD(casa_mts, casa_num_cuartos)valor_final <- temp * tasa_usd_a_pesosmejor...
precio_casa_usd <- calcularPrecioUSD(casa_mts, casa_num_cuartos)precio_casa_pesos <- precio_casa_usd * tasa_usd_a_pesos¿Qué tan grande puede ser un nombre?
¿Qué tan grande puede ser un nombre?
¡Trivia!
¿Qué tan grande puede ser un nombre?
¡Trivia!

Ideas clave
Ideas clave
- Los mejores nombres son aquellos libres de ambigüedades
Ideas clave
Los mejores nombres son aquellos libres de ambigüedades
Todos los nombres son comentarios. Da información al nombrar.
Ideas clave
Los mejores nombres son aquellos libres de ambigüedades
Todos los nombres son comentarios. Da información al nombrar.
Usa nombres más largos para scopes grandes.
3. Saber que comentar
¿Qué instructivo valdría más la pena leer?
¿Qué instructivo valdría más la pena leer?

¿Qué instructivo valdría más la pena leer?

Qué no comentar
Qué no comentar
# Suma a y bsuma <- function(a, b) { a + b}Qué no comentar
# Suma a y bsuma <- function(a, b) { a + b}# Estima los coeficientes del modelo de regresióncoeficientes <- estimaCoeficientesModelo(...)Qué no comentar
# Suma a y bsuma <- function(a, b) { a + b}# Estima los coeficientes del modelo de regresióncoeficientes <- estimaCoeficientesModelo(...)a <- c("Item1.13xrs2", "Item2.#@ ", "Item3.zszc32") # Extrae el texto antes del puntosub("\\..*", "", a)Graba tus pensamientos
Graba tus pensamientos
Comentarios "del director"
Graba tus pensamientos
Comentarios "del director"
# Sorprendentemente, un árbol binario fue un 40% más rápido que una tabla hash# para estos datos. El coste de calcular un hash era mayor que las# comparaciones izquierda/derecha.Graba tus pensamientos
Comentarios "del director"
# Sorprendentemente, un árbol binario fue un 40% más rápido que una tabla hash# para estos datos. El coste de calcular un hash era mayor que las# comparaciones izquierda/derecha.# Esta heurística puede pasar por alto algunas palabras# No pasa nada; resolver esto al 100% es difícil.Graba tus pensamientos
Comentarios "del director"
# Sorprendentemente, un árbol binario fue un 40% más rápido que una tabla hash# para estos datos. El coste de calcular un hash era mayor que las# comparaciones izquierda/derecha.# Esta heurística puede pasar por alto algunas palabras# No pasa nada; resolver esto al 100% es difícil.# Esta función está quedando compleja. Quizá deberíamos crear otra función# 'limpiaTabla()' para ayudar a refactorizar esto.Comenta los pormenores de tu código
Usa "marcadores"
Comenta los pormenores de tu código
Usa "marcadores"
# TODO: usa un algoritmo más rápidoComenta los pormenores de tu código
Usa "marcadores"
# TODO: usa un algoritmo más rápido# TODO: utilizar un formato de imágen distinto a JPEGComenta los pormenores de tu código
Usa "marcadores"
# TODO: usa un algoritmo más rápido# TODO: utilizar un formato de imágen distinto a JPEG| Marcador | Significado |
|---|---|
| TODO | Cosas que puedes hacer en un futuro |
| FIXME | Código que necesita ser reparado |
| HACK | Una solución poco elegante |
| XXX | Encontraste un problema mayor! |

Comentarios más generales (big picture)
#' A set of functions which take two sets or bag of words and measure their#' similarity or dissimilarity.Comentarios más generales (big picture)
#' A set of functions which take two sets or bag of words and measure their#' similarity or dissimilarity.#' This function retrieves the matches for a single document from an \code{lsh_buckets}#' object created by \code{\link{lsh}}.Comentarios más generales (big picture)
#' A set of functions which take two sets or bag of words and measure their#' similarity or dissimilarity.#' This function retrieves the matches for a single document from an \code{lsh_buckets}#' object created by \code{\link{lsh}}.# Este archivo contiene funciones de ayuda para hacer la interfaz de la Shiny más conveniente# para nuestros usuarios finales.Supera el bloqueo del escritor
Supera el bloqueo del escritor
# Híjole, esto se va a poner horrible si hay duplicados en el vector!!!Supera el bloqueo del escritor
# Híjole, esto se va a poner horrible si hay duplicados en el vector!!!⬇️
# Cuidado: este código no está contemplando valores duplicados4. Haz el control de flujo más sencillo de leer
Idea clave
Haz todas tus condicionales, loops, o cualquier otro control de flujo tan "natural" como sea posible. 🍈 🍌 🍓
if (length(x) >= 10)o
if (10 <= length(x))if (length(x) >= 10)o
if (10 <= length(x))Si tienes al menos 18 años.
if (length(x) >= 10)o
if (10 <= length(x))Si tienes al menos 18 años.
Si 18 años es menor que tu edad actual. 😕
if (a == b) { # Caso uno} else { # Caso dos}if (a != b) { # Caso dos} else { # Caso uno}Minimiza los bloques anidados
get_data <- function(config, output) { if (is_config_ok(config)) { if (connection_works(config)) { data <- parse_data() if (has_right_format(data)) { write_data(data, output) return(TRUE) } else { return(FALSE) } } else { stop("Problem with connection") } } else { stop("Wrong config data") } }Minimiza los bloques anidados
get_data <- function(config, output) { if (is_config_ok(config)) { if (connection_works(config)) { data <- parse_data() if (has_right_format(data)) { write_data(data, output) return(TRUE) } else { return(FALSE) } } else { stop("Problem with connection") } } else { stop("Wrong config data") } } get_data <- function(config, output) { if (bad_config(config)) { stop("Bad config") } if(!connection_works(config)) { stop("Can't access to connection") } data <- parse_data() if (!has_right_format(data)) { return(FALSE) } write_data(data, output) TRUE }Rompe grandes expresiones

Usa variables explicativas
checkmate::assertFlag(!is.null(findBucket(key)) || !isOccupied(findBucket(key)))Usa variables explicativas
checkmate::assertFlag(!is.null(findBucket(key)) || !isOccupied(findBucket(key)))👍
bucket <- findBucket(key)if(!is.null(bucket)) checkmate::assertFlag(!isOccupied(bucket))if (has_valid_id(str_extract(get_user_id(x), "\\d"))) { ...}if (has_valid_id(str_extract(get_user_id(x), "\\d"))) { ...}👍
user_id <- get_user_id(x)is_ID_valid <- has_valid_id(str_extract(user_id, "\\d"))if (is_ID_valid) { ...}Ideas clave
- Expresiones grandes son difíciles de entender, rómpelas en partes más pequeñas
Ideas clave
Expresiones grandes son difíciles de entender, rómpelas en partes más pequeñas
Usa variables explicativas que resuman expresiones lógicas
5. Extrae el subproblema
- Mira una función o bloque de código y pregúntate: "¿Cuál es el objetivo (alto nivel) de este código?"
Mira una función o bloque de código y pregúntate: "¿Cuál es el objetivo (alto nivel) de este código?"
Para cada línea de código, pregúntate: "¿Está trabajando directamente para ese objetivo? ¿O está resolviendo un subproblema no relacionado necesario para alcanzarlo?"
Mira una función o bloque de código y pregúntate: "¿Cuál es el objetivo (alto nivel) de este código?"
Para cada línea de código, pregúntate: "¿Está trabajando directamente para ese objetivo? ¿O está resolviendo un subproblema no relacionado necesario para alcanzarlo?"
Si hay suficientes líneas que resuelven un subproblema no relacionado, extrae ese código en una función separada.
# Return which element of 'list_coords' is closest to the given latitude/longitude.# Models the Earth as a perfect sphere.findClosestLocation <- function(lat, lng, list_coords) { closest_dist <- .Machine$double.xmax for(i in seq(list_coords)) { # Convert both points to radians. lat_rad <- lat * pi / 180 lng_rad <- lat * pi / 180 lat2_rad <- list_coords[[i]]$lng * pi / 180 lng2_rad <- list_coords[[i]]$lng * pi / 180 # Use the "Spherical Law of Cosines" formula. distance <- acos( sin(lat_rad) * sin(lat2_rad) + cos(lat_rad) * cos(lat2_rad) * cos(lng2_rad - lng_rad) ) if(distance < closest_dist) { closest <- list_coords[[i]] closest_dist <- distance } } return(closest)}convert2rad <- function(x) { x * pi / 180}convert2rad <- function(x) { x * pi / 180}spherical_distance <- function (lat1, lng1, lat2, lng2) {lat1_rad <- convert2rad(lat1)lng1_rad <- convert2rad(lng1)lat2_rad <- convert2rad(lat2)lng2_rad <- convert2rad(lng2)# Use the "Spherical Law of Cosines" formula.return(acos( sin(lat_rad) * sin(lat2_rad) + cos(lat_rad) * cos(lat2_rad) * cos(lng2_rad - lng_rad)))}findClosestLocation <- function(lat, lng, list_coords) { closest_dist <- .Machine$double.xmax for(i in seq(list_coords)) { distance <- spherical_distance(lat, lng, list_coords[[i]]$lat, list_coords[[i]]$lng) if(distance < closest_dist) { closest <- list_coords[[i]] closest_dist <- distance } } return(closest)}findClosestLocation <- function(lat, lng, list_coords) { closest_dist <- .Machine$double.xmax for(i in seq(list_coords)) { distance <- spherical_distance(lat, lng, list_coords[[i]]$lat, list_coords[[i]]$lng) if(distance < closest_dist) { closest <- list_coords[[i]] closest_dist <- distance } } return(closest)}¡Trivia!
6. Una tarea a la vez

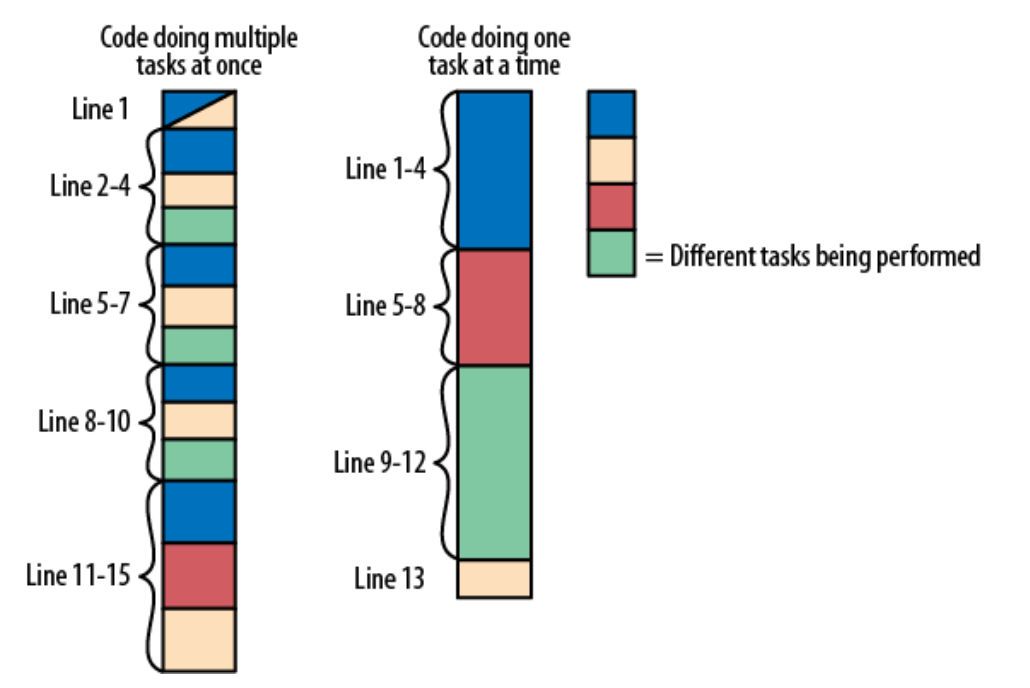
Fuente: The Art Of Readable Code
vote_changed <- function(old_vote, new_vote) { score <- get_score() if (new_vote != old_vote) { if (new_vote == "up") { score <- score + ifelse(old_vote == "down", 2, 1) } else if (new_vote == "down") { score <- score - ifelse(old_vote == "up", 2, 1) } else if (new_vote == "") { score <- score + ifelse(old_vote == "up", -1, 1) } } set_score(score)}vote_value <- function(vote) { switch (vote, "up" = 1, "down" = -1, 0 )}vote_value <- function(vote) { switch (vote, "up" = 1, "down" = -1, 0 )}la siguiente función requiere menor esfuerzo físico:
vote_value <- function(vote) { switch (vote, "up" = 1, "down" = -1, 0 )}la siguiente función requiere menor esfuerzo físico:
vote_changed <- function(old_vote, new_vote) { score <- get_score() score <- score - vote_value(old_vote) # Remove the old vote score <- score + vote_value(new_vote) # Add the new vote set_score(score)}Para finalizar
Para finalizar
- Estos consejos son extrapolables a cualquier lenguaje.
Para finalizar
Estos consejos son extrapolables a cualquier lenguaje.
Piensa en el teorema de la legibilidad cuando escribas nuevo código.
Para finalizar
Estos consejos son extrapolables a cualquier lenguaje.
Piensa en el teorema de la legibilidad cuando escribas nuevo código.
Lee código de alguien más. Los paquetes populares del tidyverse son un buena guía.
Para finalizar
Estos consejos son extrapolables a cualquier lenguaje.
Piensa en el teorema de la legibilidad cuando escribas nuevo código.
Lee código de alguien más. Los paquetes populares del tidyverse son un buena guía.
Siempre habrá excepciones, pero asegúrate que sea una buena excusa.